

What is SQL?
SQL stands for ‘Structured Query Language’ and is used for communicating with databases. According to ANSI, SQL is the standard query language used for maintaining relational database management systems (RDBMS) and also for performing different operations of data manipulation on different types of data. Basically, it is a database language that is used for the creation and deletion of databases, and it can be used to fetch and modify the rows of a table and also for multiple other things.
What are the subsets of SQL?
The main significant subsets of SQL are:
- DDL(Data Definition Language)
- DML(Data Manipulation Language)
- DCL(Data Control Language)
- TCL(Transaction Control Language)
Explain the different types of SQL commands.
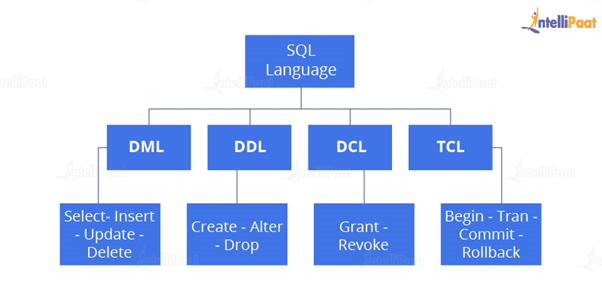
- Data Definition Language: DDL is that part of SQL which defines the data structure of the database in the initial stage when the database is about to be created. It is mainly used to create and restructure database objects. Commands in DDL are:
- Create table
- Alter table
- Drop table
- Data Manipulation Language: DML is used to manipulate the already existing data in the database. That is, it helps users retrieve and manipulate the data. It is used to perform operations such as inserting data into the database through the insert command, updating the data with the update command, and deleting the data from the database through the delete command.
- Data Control Language: DCL is used to control access to the data in the database. DCL commands are normally used to create objects related to user access and also to control the distribution of privileges among users. The commands that are used in DCL are Grant and Revoke.
- Transaction Control Language: It is used to control the changes made by DML commands. It also authorizes the statements to assemble in conjunction into logical transactions. The commands that are used in TCL are Commit, Rollback, Savepoint, Begin, and Transaction.
What are the different types of database management systems?
Database Management System is classified into four types:
- Hierarchical database: It is a tree-like structure where the data is stored in a hierarchical format. In this database, the parent may have many children but a child should have a single parent.
- Network database: It is presented as a graph that allows many-to-many relationships. This database allows children to have multiple children.
- Relational database: A relational database is represented as a table. The values in the columns and rows are related to each other. It is the most widely used database because it is easy to use.
- Object-Oriented database: The data values and operations are stored as objects in this database. All these objects have multiple relationships between them.
What are the usages of SQL?
These are the operations that can be performed using SQL database:
- Creating new databases
- Inserting new data
- Deleting existing data
- Updating records
- Retrieving the data
- Creating and dropping tables
- Creating functions and views
- Converting data types
What is a default constraint?
Constraints are used to specify some sort of rules for processing data and limiting the type of data that can go into a table. Now, let’s understand the default constraint.
The default constraint is used to define a default value for a column so that the default value will be added to all the new records if no other value is specified.
What is a primary key?
A primary key is used to uniquely identify all table records. It cannot have NULL values, and it must contain unique values. A table can have only one primary key that consists of single or multiple fields.
// CREATE TABLE Employee ( ID int NOT NULL, Employee_name varchar(255) NOT NULL, Employee_designation varchar(255), Employee_Age int, PRIMARY KEY (ID) );
What is a Unique Key?
The key which can accept only the null value and cannot accept the duplicate values is called Unique Key. The role of the unique key is to make sure that each column and row are unique.
The syntax will be the same as the Primary key. So, the query using a Unique Key for the Employee table will be:
//
CREATE TABLE Employee (
ID int NOT NULL,
Employee_name varchar(255) NOT NULL,
Employee_designation varchar(255),
Employee_Age int,
UNIQUE(ID)
);What is the difference between Primary key and Unique Key?
Both Primary and Unique key carry unique values but the primary key can not have a null value where the Unique key can. And in a table, there cannot be more than one Primary key but unique keys can be multiple.
What is a foreign key?
A foreign key is an attribute or a set of attributes that references to the primary key of some other table. Basically, it is used to link together two tables.
CREATE TABLE Orders (
OrderID int NOT NULL,
OrderNumber int NOT NULL,
PersonID int,
PRIMARY KEY (OrderID),
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID)
)What is an index?
Indexes help speed up searching in the database. If there is no index on any column in the WHERE clause, then SQL Server has to skim through the entire table and check each and every row to find matches, which might result in slow operation on large data.
Indexes are used to find all rows matching with some columns and then to skim through only those subsets of the data to find the matches.
Syntax:
CREATE INDEX INDEX_NAME ON TABLE_NAME (COLUMN)Explain the types of indexes.

Single-column Indexes: A single-column index is created for only one column of a table.
Syntax:
CREATE INDEX index_name ON table_name(column_name);
Composite-column Indexes: A composite-column index is an index created for two or more columns of the table.
Syntax:
CREATE INDEX index_name ON table_name (column1, column2)
Unique Indexes: Unique indexes are used for maintaining the data integrity of the table. They do not allow multiple values to be inserted into the table.
Syntax:
CREATE UNIQUE INDEX index
ON table_name(column_nameWhy do we use the FLOOR function in SQL Server?
The FLOOR() function helps us to find the largest integer value to a given number which can be an equal or lesser number.
State the differences between clustered and non-clustered indexes.
- Clustered index: It is used to sort the rows of data by their key values. A clustered index is like the contents of a phone book. We can open the book at ‘David’ (for ‘David, Thompson’) and find information for all Davids right next to each other. Since the data is located next to each other, it helps a lot in fetching data based on range-based queries. Also, the clustered index is actually related to how the data is stored. There is only one clustered index possible per table.
- Non-clustered index: It stores data at one location and indexes at some other location. The index has pointers that point to the location of the data. As the index in the non-clustered index is stored in different places, there can be many non-clustered indexes for a table.
What is AUTO_INCREMENT?
AUTO_INCREMENT is used in SQL to automatically generate a unique number
whenever a new record is inserted into a table.
Since the primary key is unique for each record, we add this primary field as the
AUTO_INCREMENT field so that it is incremented when a new record is inserted.
The AUTO-INCREMENT value starts from 1 and is incremented by 1 whenever a
new record is inserted.
Syntax:
CREATE TABLE Employee(Employee_id int NOT NULL AUTO-INCREMENT,Employee_name varchar(255) NOT NULL,int, PRIMARY KEY (Employee_id) )Employee_designation varchar(255) Age





No comments:
Post a Comment